Detect Numbers from a Display with LLMs
For the displays cut out from my Minol heat usage meter I trained a CNN to classify the cut out numbers years ago. I plan on retraining and reevaluating this code, but in 2024 I have to try to use the current GPT4 model and the current image processing capable of Gemini for this.
Gemini 1.5 Flash
So I did some exploration on how good this works and first started with Gemini 1.5 Flash. This failed horrendously. Gemini most of the time returns 255 as number on the display, and I was not encouraged to experiment further with Gemini.
Examples:
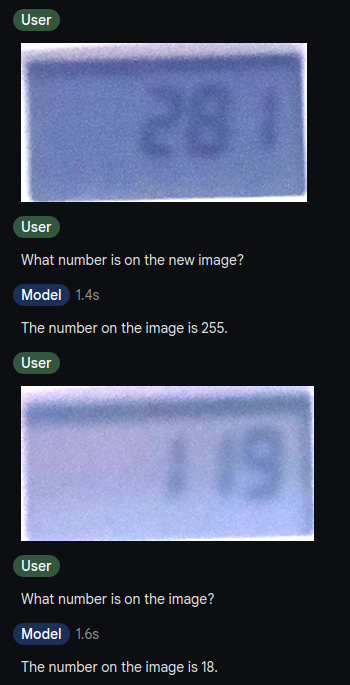
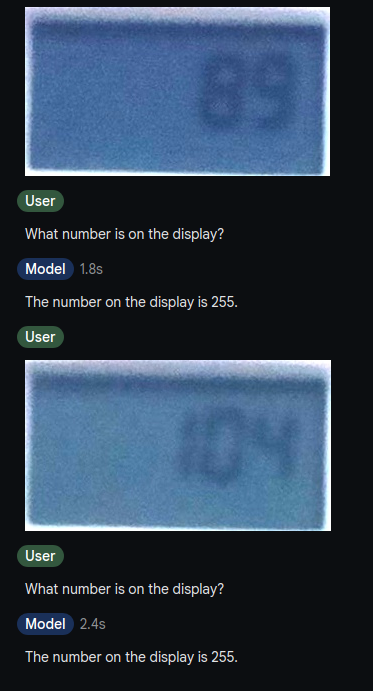
GPT-4o-mini
Next I tried OpenAIs GPT-4o-mini and the results felt really good. Even when nothing is on the display it didn't hallucinate:

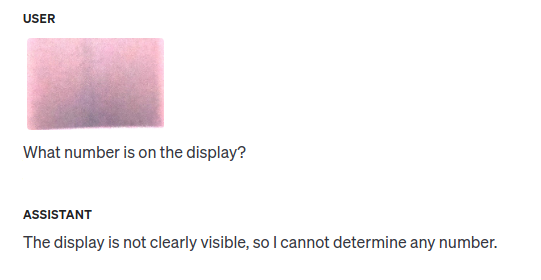
Automate
So I decided that a few Euros are worth it to automate this and try a reasonable sample of images.
Calling OpenAI completion with an image inline:
def query_gpt(img_binary): img_base64 = base64.b64encode(img_binary).decode("utf-8") img_str = f"data:image/jpeg;base64,{img_base64}" client = OpenAI(api_key=API_KEY) response = client.chat.completions.create( model="gpt-4o-mini", messages=[{ "role": "user", "content": [ { "type": "text", "text": "What are the numbers on the display? Please answer only with the number.", }, {"type": "image_url", "image_url": {"url": img_str}}, ],}], max_tokens=300, ) return response.choices[0].message.content
The img_binary is either the field from the SQLite table, or a fp.read() of an actual image file.
Scrolling over the results I see errors -- time to evaluate this. So I manually labeled the images by writing the correct value into a new field in the SQLite table. To do this I used a bit of Javascript and the new Datasette JSON write API from the current 1.0alpha version of Datasette. More on this (including some code) in the next blog post.
So after manually either accept the GPT value or set a new value, the results are not as good as it felt when scrolling over them. Only 57% of the GPT answers are correct.
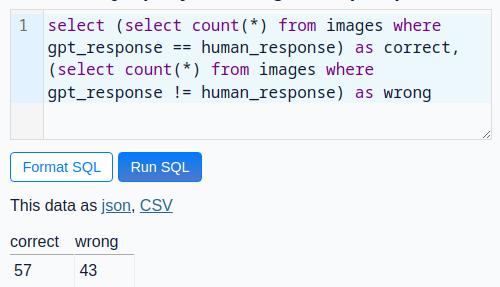
The manual labeling was really fast. And I didn't need to fiddle around with the messy images: Some were cut-off, some not perfectly aligned and the ones that are really good have correct values from the LLM. So I will use GPT-4o-mini to label the rest of the images and then decide if I manually correct them or not. To get a trend it is enough to have a good value per day. Filtering should not be that hard, because the value should be higher than the previous one and the difference per day cannot be too much.