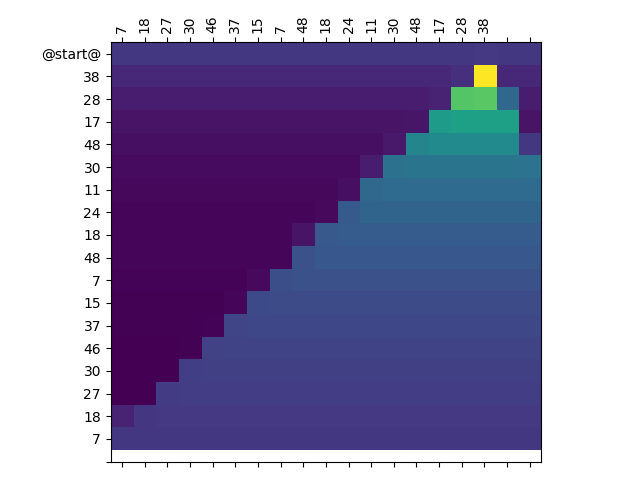
AllenNLP: sequence to sequence attention plots
As follow-up to last weeks post about implementing a reversing sequence-to-sequence model in AllenNLP, this post is about visualizing the attention.
Same as last week this post was tested with Python 3.7 and AllenNLP 0.8.4.
And all code is in this repository: https://github.com/mfa/allennlp-reverse-seq2seq/
To get the information needed to plot the attentions a few methods of the SimpleSeq2Seq class in simple_seq2seq.py have to be modified.
The lines changed compared to version 0.8.4 of AllenNLP:
diff --git a/simple_seq2seq.py b/simple_seq2seq.py index 849da8a..9c7e3da 100644 --- a/simple_seq2seq.py +++ b/simple_seq2seq.py @@ -323,6 +323,7 @@ class SimpleSeq2Seq(Model): step_logits: List[torch.Tensor] = [] step_predictions: List[torch.Tensor] = [] + attn: List[torch.Tensor] = [] for timestep in range(num_decoding_steps): if self.training and torch.rand(1).item() < self._scheduled_sampling_ratio: # Use gold tokens at test time and at a rate of 1 - _scheduled_sampling_ratio @@ -338,6 +339,8 @@ class SimpleSeq2Seq(Model): # shape: (batch_size, num_classes) output_projections, state = self._prepare_output_projections(input_choices, state) + if not self.training: + attn.append(torch.squeeze(state["attention_weights"])) # list of tensors, shape: (batch_size, 1, num_classes) step_logits.append(output_projections.unsqueeze(1)) @@ -358,6 +361,9 @@ class SimpleSeq2Seq(Model): output_dict = {"predictions": predictions} + if not self.training: + output_dict["attentions"] = torch.unsqueeze(torch.stack(attn), 0) + if target_tokens: # shape: (batch_size, num_decoding_steps, num_classes) logits = torch.cat(step_logits, 1) @@ -412,7 +418,8 @@ class SimpleSeq2Seq(Model): if self._attention: # shape: (group_size, encoder_output_dim) - attended_input = self._prepare_attended_input(decoder_hidden, encoder_outputs, source_mask) + attended_input, input_weights = self._prepare_attended_input(decoder_hidden, encoder_outputs, source_mask) + state["attention_weights"] = input_weights # shape: (group_size, decoder_output_dim + target_embedding_dim) decoder_input = torch.cat((attended_input, embedded_input), -1) @@ -451,7 +458,7 @@ class SimpleSeq2Seq(Model): # shape: (batch_size, encoder_output_dim) attended_input = util.weighted_sum(encoder_outputs, input_weights) - return attended_input + return attended_input, input_weights @staticmethod def _get_loss(logits: torch.LongTensor,
The same diff in the github repository: https://github.com/mfa/allennlp-reverse-seq2seq/commit/d9ca4c9c5f8f489b14f091a974b7e7a9cdbd7fef
Additionally the class name and registered name are changed to avoid duplicate naming.
Now we have to use the new model in the configuration and train with an additional parameter:
For prediction we need a custom predictor that adds source and target sequence to plot them later.
The plotting code can be seen in the repository: https://github.com/mfa/allennlp-reverse-seq2seq/blob/master/tools/plot_attention.py
To predict and than generate the plots run:
allennlp predict output/model.tar.gz --use-dataset-reader examples.csv --predictor my_seq2seq --output-file output/examples.output --include-package library python tools/plot_attention.py
One example plot looks like this: