Adding an Atom Feed to Authors in ACL Anthology
Reading all abstracts of all papers in the Computational Linguistics field is a full time job. So I wanted to filter the papers to the authors in my particular subfield only. Even when they submit a paper to a workshop or a conference I am not following actively I want to have a way to get notified. Having a RSS feed or an Atom feed seems like the best choice.
Unfortunately there is no author feed for the ACL Anthology. Adding one was discussed in an issues on Github. Since I have no clue about implementing this feature into Hugo, I solved this with implementing my own feed generator. My feed generator is named acl-feed and is reading the HTML page of an author on the anthology and converts their publications into an atom feed.
The code is written in Python using (async) Flask, beautifulsoup and feedgen.
The live version is hosted at https://acl-feed.madflex.de/ and looks like this:
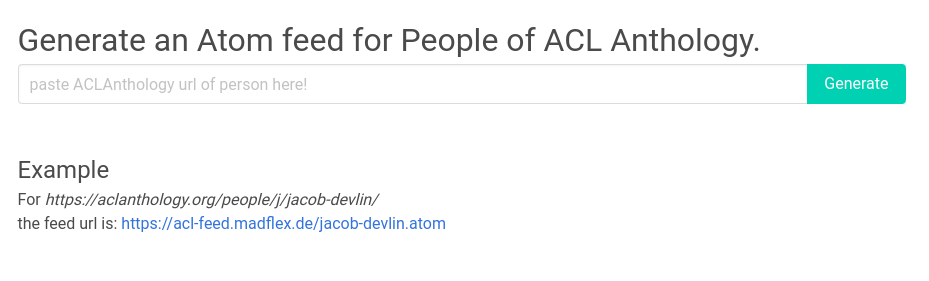
Since there is no publication date in the HTML page the updated timestamp in the feed is always the current date and time. This could only be solved by generating the feed with the full data of the anthology. So when there is an author feed generated by the ACL Anthology I am happy to switch this service off and use their feed.
