Spa towns starting with "Bad" and OSM
A few days ago I was sitting at a train station in Bad Wildbad waiting for a train home because of a flat tire on my bike. I was thinking about spa town distribution and cities which name starts with "Bad" (German for "bath") which is a pretty solid indicator for a spa town in Germany. Of course there are many spa towns in Germany that don't start with "Bad". Probably they could be collected via a wikidata query on subclass of spa town but I wanted to solve this with Openstreetmap only.
To get the datasets of all cities, towns, villages and suburbs starting with "Bad" we use the same Python code as in a previous blogpost about the overpass api. The changes needed are:
City names can be in nodes or ways (ways contain the borders of the city). Nodes seem more common so limit to those. The selector "name" should start with "Bad " and "place" should be limited to a list of town-link places. The query with a trailing space will filter out "Baden Baden", but also some false positives, i.e. Badevel, Badonvilliers-Gérauvilliers and a few more.
The query result is messy. A few cities are duplicates (i.e. Bad Salzuflen; Bad Sooden, Bad Sooden-Allendorf - both town vs. suburb). But removing all "suburbs" will remove a lot more valid cities. Without manual work this will not be without error.
Three examples of nodes returned show that the attached tags differ a lot:
First: A way should be used; I ignore them for now. This city will have empty metadata.
{ "type": "node", "id": 25728642, "lat": 50.2276774, "lon": 9.3485142, "tags": { "name": "Bad Orb", "note": "Alle Daten der Stadt Bad Orb sind in der zugehörigen Grenzrelation. Dieser node dient nur zur Markierung der Ortsmitte.", "place": "town" } }
Second: The fields have no prefixes. Kind of what I expected and most cities look like this.
{ "type": "node", "id": 26120920, "lat": 51.5911653, "lon": 12.5856428, "tags": { "ele": "98", "name": "Bad Düben", "place": "town", "population": "8000", "postal_code": "04849", "website": "https://www.bad-dueben.de", "wikidata": "Q12041", "wikipedia": "de:Bad Düben" } }
Third: A lot of extra fields prefixed with OpenGeoDB. I ignore this fields and hope the other fields are filled good enough.
{ "type": "node", "id": 21635999, "lat": 47.5062921, "lon": 10.3699251, "tags": { "ele": "825", "name": "Bad Hindelang", "openGeoDB:community_identification_number": "09780123", "openGeoDB:is_in_loc_id": "270", "openGeoDB:layer": "6", "openGeoDB:license_plate_code": "OA", "openGeoDB:loc_id": "13927", "openGeoDB:telephone_area_code": "08324", "place": "town", "population": "4899", "postal_code": "87541", "wikidata": "Q522573", "wikipedia": "de:Bad Hindelang" } }
The resulting list of elements is then converted into a Pandas Dataframe:
df = pd.DataFrame.from_records( [ # all fields, excluding "tags" {k:v for k, v in d.items() if k != "tags"} # merge tags to toplevel | {k: v for k, v in d["tags"].items()} for d in data ] )
Next we want to find out which tags are mostly filled:
# sum emptiness of fields; subtract from number of rows and sort by highest number print( dict( pd.isna(df) .sum(axis=0) .apply(lambda x: len(df) - x) .sort_values(ascending=False) ) )
The most common ones are as expected the essential parts of the query:
"place": 237, "name": 237, "lon": 237, "lat": 237, "id": 237, "type": 237, "population": 165, "wikidata": 158, "wikipedia": 124, "postal_code": 62,
From 237 datasets 158 datasets have a link to Wikidata and 124 one to Wikipedia. And even less have a postal_code. One could argue that this information could be found elsewhere. But it would be convenient to have the population filled or a wikidata link to query more information.
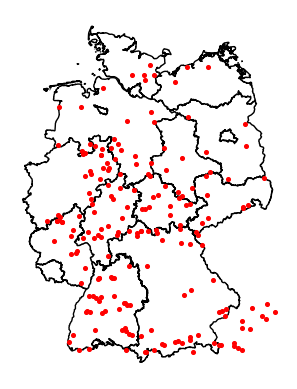
Finally lets use the code from the previous blogpost to plot all the spa cities starting with "Bad " on a Germany map. As seen on the plot, some spa cities are in Austria or in Switzerland because the bounding box used in the query is a rectangle and not the exact borders of Germany.