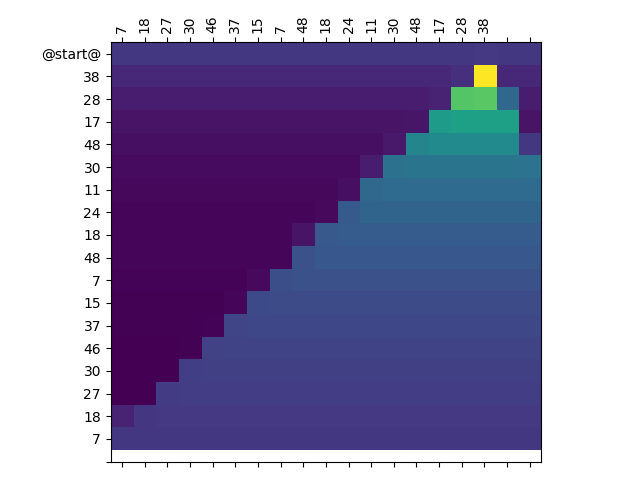
AllenNLP: Run on Production with Django
This post describes howto run a custom AllenNLP model within Django and Django Rest Framework.
The View code:
import json from rest_framework import status, viewsets from rest_framework.parsers import JSONParser from rest_framework.response import Response from .utils import predict class PredictViewSet(viewsets.ViewSet): parser_classes = (JSONParser,) def create(self, request): """ example call: curl -X POST "http://localhost:8000/" -H "content-type: application/json" --data '{"source": "1/5/2003"}' """ if isinstance(request.data, str): data = json.loads(request.data) else: data = request.data if not "source" in data: return Response( 'Format: {"source": string}', status=status.HTTP_400_BAD_REQUEST ) return Response(predict(data.get("source")))
And the utils.py with the predict method.
from allennlp.common.util import import_submodules from allennlp.models.archival import load_archive from allennlp.predictors import Predictor def predict(source): # register custom model code # the library code is in the same Django app (main) in the folder "library" import_submodules("main.library") # load model without using cuda archive = load_archive("../models/model.tar.gz", cuda_device=-1) # select predictor needed for this model predictor = Predictor.from_archive(archive, "seq2seq") result = predictor.predict_json({"source": source}) # add a confidence bool to help ignoring bad results confident = True if abs(result["class_log_probabilities"][0]) < 0.05 else False return { "predicted": "".join(result["predicted_tokens"]), "probability": result["class_log_probabilities"][0], "confident": confident, }