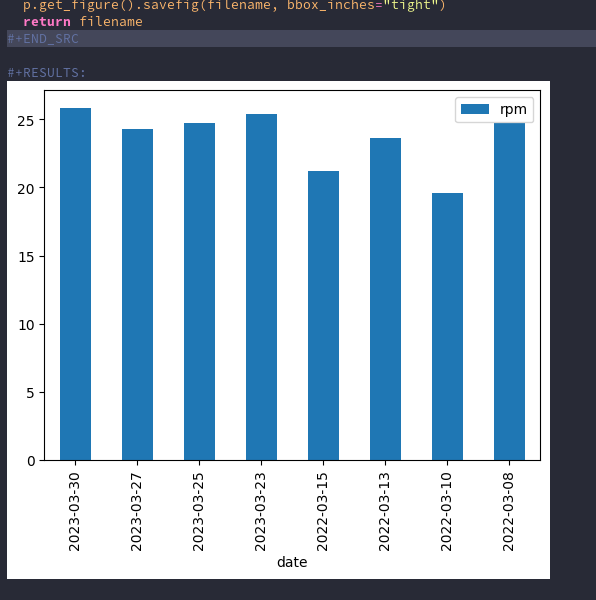
Intersect using SpatiaLite
The next step in my geo-experiments journey is to find GPX tracks that pass through an entry polygon and an exit polygon. To start this the GPX needs to be split up into points. For now I used togeojson and will do this in proper Python code later. The resulting "coordinates" list will then be processed via SpatiaLite.
GeoJson
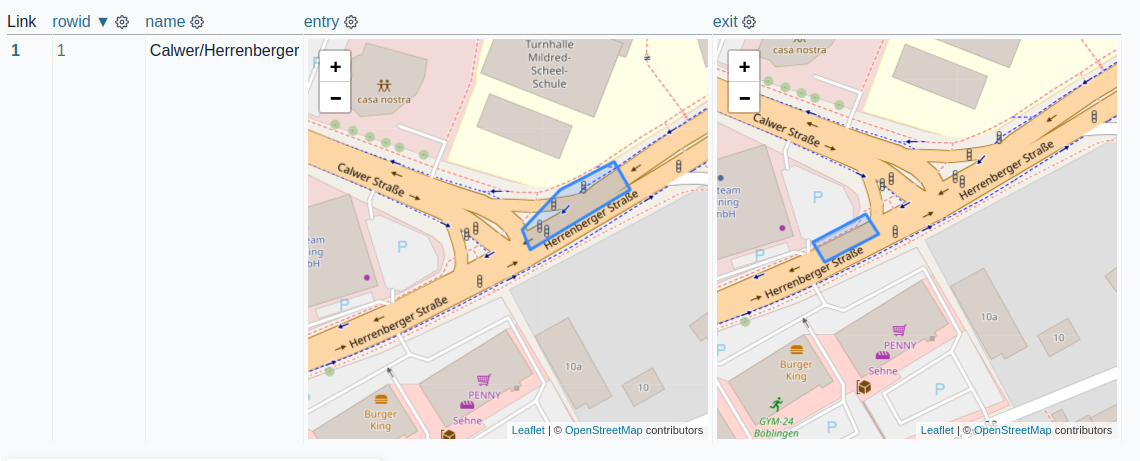
First we need a database entry with one entry polygon and one exit polygon. Using sqlite-utils this could look like this:
DATA=$(cat <<'END_HEREDOC' {"name": "Calwer/Herrenberger", "entry": {"type":"Feature","properties":{"type": "entry"}, "geometry":{"type":"Polygon", "coordinates":[[[9.003386,48.683486],[9.003185,48.68335],[9.003226,48.683275], [9.003769,48.683492],[9.003679,48.68359],[9.003386,48.683486]]]}}, "exit": {"type":"Feature","properties":{"type": "exit"}, "geometry":{"type":"Polygon", "coordinates":[[[9.002798,48.683225],[9.002868,48.683157],[9.002577,48.683058], [9.002519,48.683127],[9.002798,48.683225]]]}}} END_HEREDOC ) echo $DATA | sqlite-utils insert crossings.db crossings -
The result is a sqlite database with one dataset in the crossings table.
Using Datasette and datasette-leaflet-geojson the imported dataset looks like this:
One example GPX file cropped to the area that is of interest as GeoJSON:
{"type": "Feature", "geometry": {"type": "LineString", "coordinates": [
[9.004165, 48.683825, 463], [9.004133, 48.683812, 463], [9.004092, 48.683797, 463.2], [9.004047, 48.683779, 463.2],
[9.003999, 48.68376, 463.2], [9.003947, 48.683739, 463.2], [9.003895, 48.683718, 463.4],
[9.003845, 48.683697, 463.4], [9.003795, 48.683676, 463.4], [9.003744, 48.683656, 463.6],
[9.003694, 48.683636, 463.6], [9.003652, 48.683621, 463.6], [9.003619, 48.683609, 463.6],
[9.0036, 48.683603, 463.6], [9.003594, 48.6836, 463.6], [9.003592, 48.683598, 463.6], [9.003592, 48.683598, 463.6],
[9.003592, 48.683598, 463.6], [9.003592, 48.683598, 463.6], [9.003567, 48.683579, 463.6],
[9.003524, 48.683547, 463.6], [9.003495, 48.683526, 463.8], [9.003466, 48.683503, 463.8],
[9.003438, 48.683482, 463.8], [9.003408, 48.683466, 463.8], [9.003378, 48.683455, 463.8],
[9.003354, 48.683447, 463.8], [9.00334, 48.683443, 463.8], [9.003337, 48.683441, 463.8],
[9.003337, 48.683441, 463.8], [9.003337, 48.683441, 463.8], [9.003337, 48.683441, 463.8],
[9.003337, 48.683441, 463.8], [9.003328, 48.683438, 463.8], [9.003304, 48.683428, 463.6],
[9.00327, 48.683415, 463.6], [9.003228, 48.6834, 463.6], [9.003178, 48.683381, 463.4],
[9.003123, 48.683358, 463.2], [9.003064, 48.683334, 463], [9.002998, 48.683309, 463],
[9.002928, 48.683286, 463], [9.002856, 48.683261, 462.8], [9.002785, 48.683234, 462.8],
[9.00271, 48.683207, 462.6], [9.002634, 48.683182, 462.6], [9.002555, 48.68316, 462.6],
[9.002476, 48.683139, 462.4], [9.002398, 48.683118, 462.4], [9.002318, 48.683098, 462.2],
[9.002237, 48.683079, 462.2], [9.002154, 48.683056, 462], [9.002073, 48.683034, 461.8]]}}
Plotted together with the polygons:
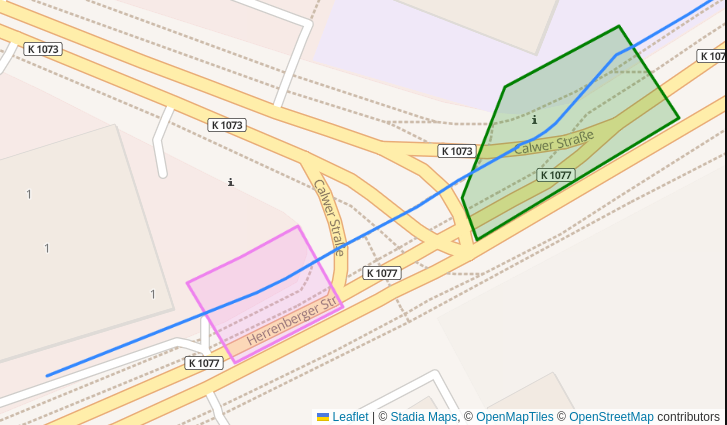
To create this plot I used leaflet this way:
var example = [ // entry {"type":"Feature","properties":{"type":"entry"},"geometry":{"type":"Polygon","coordinates":[[[9.0033,48.683546],[9.003185,48.68335],[9.003226,48.683275],[9.003769,48.683492],[9.003608,48.683654],[9.0033,48.683546]]]}}, // exit {"type":"Feature","properties":{"type":"exit"},"geometry":{"type":"Polygon","coordinates":[[[9.002745,48.683301],[9.002868,48.683157],[9.002577,48.683058],[9.002447,48.6832],[9.002592,48.683245],[9.002745,48.683301]]]}}, // track {"type": "Feature", "geometry": {"type": "LineString", "coordinates": [...<see above>...]}} ] L.geoJSON(example, { style: function(feature) { if (feature.properties){ switch (feature.properties.type) { case 'entry': return {color: "green"} case 'exit': return {color: "violet"} }}}}).addTo(map);
SpatiaLite
But how can we calculate if a track is actually crossing entry and exit in SQL?
First we need libspatialite (for example on ArchLinux):
# https://archlinux.org/packages/extra/x86_64/libspatialite/ pacman -S libspatialite
The next step is to verify via SQL if the track is crossing both polygons. This code needs shapely and sqlite-utils installed.
import json from shapely.geometry import shape from sqlite_utils.db import Database # create a new database db = Database("crossings_demo.db") # add the spatialize tables db.init_spatialite("/usr/lib/mod_spatialite.so") # path to library file # table for polygons table = db["areas"] table.insert_all([ {"id": 1, "type": "entry", "geojson": { "type": "Polygon", "coordinates": [ [ [9.003386, 48.683486], [9.003185, 48.68335], [9.003226, 48.683275], [9.003769, 48.683492], [9.003679, 48.68359], [9.003386, 48.683486], ]]}}, {"id": 2, "type": "exit", "geojson": { "type": "Polygon", "coordinates": [ [ [9.002798, 48.683225], [9.002868, 48.683157], [9.002577, 48.683058], [9.002519, 48.683127], [9.002798, 48.683225], ]]}}, ], pk="id" ) # add a geometry column table.add_geometry_column(f"geometry", "POLYGON") # convert geojson to geometry field for row in table.rows: wkt = shape(json.loads(row["geojson"])).wkt db.execute( f"update areas set geometry = GeomFromText(?, 4326) where id=?", [wkt, row["id"]], ) # test if points are in areas for x, y in ( (9.003473, 48.683439), # in entry (9.002692, 48.683142), # in exit (9, 48), # outside of both ): r = db.query( "select :x, :y, type, WITHIN(MakePoint(:x, :y), areas.geometry) as inside from areas", {"x": x, "y": y} ) print(list(r)) # returns # [{':x': 9.003473, ':y': 48.683439, 'type': 'entry', 'inside': 1}, # {':x': 9.003473, ':y': 48.683439, 'type': 'exit', 'inside': 0}] # [{':x': 9.002692, ':y': 48.683142, 'type': 'entry', 'inside': 0}, # {':x': 9.002692, ':y': 48.683142, 'type': 'exit', 'inside': 1}] # [{':x': 9, ':y': 48, 'type': 'entry', 'inside': 0}, {':x': 9, ':y': 48, 'type': 'exit', 'inside': 0}] # query for a track intersection with the entry/exit areas track = {"type": "LineString", "coordinates": [ [9.003845, 48.683697], [9.003795, 48.683676], [9.003744, 48.683656], [9.003694, 48.683636], [9.003652, 48.683621], [9.003619, 48.683609], [9.003592, 48.683598], [9.003592, 48.683598], [9.003567, 48.683579], [9.003337, 48.683441], [9.003328, 48.683438], [9.003304, 48.683428], [9.00271, 48.683207], [9.002634, 48.683182], [9.002555, 48.68316], ]} wkt = shape(track).wkt r = db.query( "select type, Intersects(GeomFromText(?), Envelope(areas.geometry)) as crosses from areas", [wkt], ) print(list(r)) # returns # [{'type': 'entry', 'crosses': 1}, {'type': 'exit', 'crosses': 1}]
Personal todos here:
the track
Intersectsfor exit only when using anEnvelopearound itthis could be faster with a
SpatialIndexbut I couldn't get it to workHow is the performance when the track is a lot of points (i.e. 100km gpx file)