Add more RaspberryPI Sensors to Homeassistant
Currently I have 7 RaspberryPIs deployed. Most of them have have a BME280 sensor and some have additionally different sensors. For my future self I want to have instructions on how to reinstall everything. The first step was the Packer-Ansible setup described in the previous blogpost to get a ready to use base system with wifi, vpn and some base settings. This is the next step by starting a git repo with sensors that I use to push to Homeassistant.
For example the most common sensor I use: the BME280.
To use this on a PI the sensor needs to be connected to the I2C pins and I2C needs to be activated on the RaspberryPI (i.e. by using raspi-config).
The Python package I use is RPi.bme280 and the code to push looks like this:
#!/usr/bin/python import requests import smbus2 import bme280 from pathlib import Path def push(data, secret): r = requests.post( f"http://192.168.0.99:8123/api/webhook/{secret}", json={ "temperature": round(data["temperature"], 1), "pressure": int(data["pressure"]), "humidity": int(data["humidity"]), }, ) assert r.status_code == 200 # copy webhook secret into file .secret secret = (Path(__file__).parent / ".secret").open().read().strip() address = 0x76 bus = smbus2.SMBus(1) bme280.load_calibration_params(bus, address) sensor = bme280.sample(bus, address) push({ "temperature": sensor.temperature, "pressure": sensor.pressure, "humidity": sensor.humidity, }, secret)
The secret in the file .secret is the webhook_id used in homeassistant.
There is no additional security to knowing this webhook_id.
The homeassistant config looks like this:
template: - trigger: - platform: webhook webhook_id: !secret zero6-bme allowed_methods: - POST local_only: false unique_id: "zero6" sensor: - name: "zero6 Temperature" state: "{{ trigger.json.temperature }}" unit_of_measurement: "°C" device_class: temperature unique_id: "zero6_temperature" - name: "zero6 Humidity" state: "{{ trigger.json.humidity }}" unit_of_measurement: "%" device_class: humidity unique_id: "zero6_humidity" - name: "zero6 Pressure" state: "{{ trigger.json.pressure }}" unit_of_measurement: "hPa" device_class: atmospheric_pressure unique_id: "zero6_pressure"
The other sensors added to the Repository are: SCD30, BME680, BH1750, BMP180 and ADS1015.
Every sensor has a push.py script and a readme howto install the packages needed.
Everything is documented in https://github.com/mfa/ha-sensors.
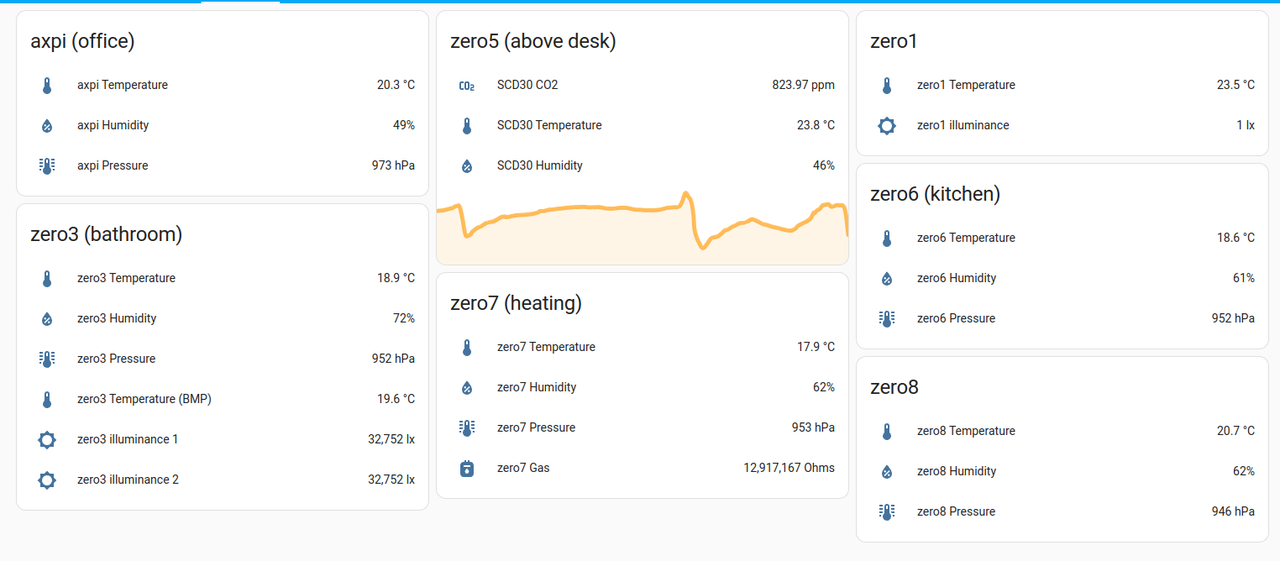
Screenshot of some of the sensors in my homeassistant dashboard: