Homeassistant: Monitor other systems
I wanted to monitor different computers with my Homeassistant installation. First a PC that runs at a different place that I use for GPU training and compute. This PC runs Archlinux. The other system(s) I want to monitor are Raspberry PIs. Here especially disk usage and memory overflow.
There is a package for glances in Archlinux and in Raspberry PI OS:
# archlinux sudo pacman -S glances python-bottle python-dateutil ## gpu support sudo yay -S python-py3nvml # Raspberry PI OS / Debian sudo apt install glances python3-bottle python3-dateutil
The Debian package installs a lot of packages I actually don't need, but on the other hand I don't want to build my own package or install into a virtualenv.
The second step for installation is to prepare a systemd service.
For both Archlinux and Debian/Raspberry PI OS we need to edit the systemd file, because the default there is -s but we need -w.
On Debian we also need to remove the -B 127.0.0.1 to access the service from another system.
Instructions:
# disable existing one (only needed for Debian/Raspberry PI OS) sudo systemctl stop glances sudo systemctl disable glances # copy the template sudo cp /lib/systemd/system/glances.service /etc/systemd/system/glances-homeassistant.service # change "glances -s" to "glances -w" and remove the "-B 127.0.0.1" if needed sudo vim /etc/systemd/system/glances-homeassistant.service # reload changed file sudo systemctl daemon-reload # start service sudo systemctl start glances-homeassistant # also start after reboot sudo systemctl enable glances-homeassistant
Finally we setup the Sensor in Homeassistant using the Glances integration.
Setup with correct IP address, without any Username/Password, keep Port 61208, set version to 3 and no SSL.
Adding a username/password seems to be not that hard, but I use this in my VPN and actually don't think this information is in need for more security.
Example using the Glances Card:

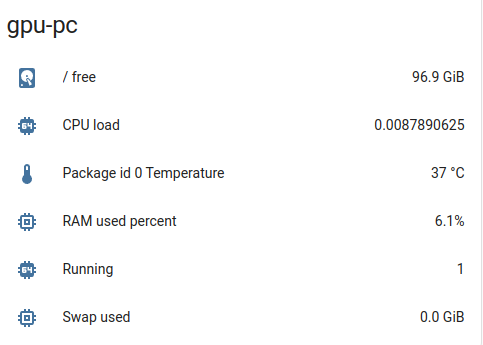
And a very idle PC displayed in Homeassistant using the Entities Card: