I use AWS for work and wanted to have an alternative S3 for a private project.
Tigris seems to be ready to use from a Fly.io App so lets try this to receive a webhook and save the data in a bucket.
The setup is on purpose very similar to the version using supabase I blogged about at the beginning of last year.
The full code is on Github in https://github.com/mfa/ax-tigris-fly/.
First create a bucket for an already existing/launched Fly App:
fly storage create -n ax-s3-demo
The secrets for this bucket are automatically added to the app.
The code to write into the bucket uses boto3 the same way we would for AWS S3.
So writing the json we received into the bucket could look like this:
import boto3
import io
service = boto3.client("s3", endpoint_url="https://fly.storage.tigris.dev")
buf = io.BytesIO()
buf.write(json.dumps(dataset).encode())
buf.seek(0)
service.upload_fileobj(buf, "ax-s3-demo", f'{dataset["uid"]}.json')
The dataset is writen into a BytesIO file object which is then uploaded to the Tigris S3 storage.
The code assumes that in the dataset a field named "uid" exists which can be used for the filename.
To verify the code (the one deployed to Fly.io) worked, we take a look into the Tigris dashboard:
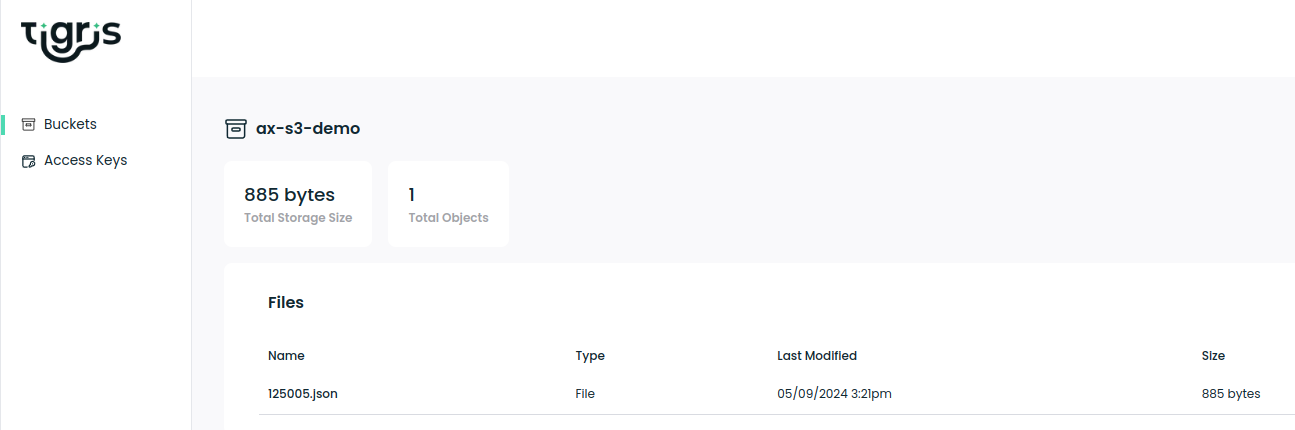
Yay, we have a file in there, but how do we get the data loaded from a different place.
For me this is not within Fly.io so I need new credentials which can be obtained from the Tigris dashboard unter "Access Keys".
We create a new access key that can read only the one bucket we need.
The actual variable parts here are "Access Key ID" and "Secret Access Key".
Code to download all files from the bucket onto the local filesystem:
import boto3
AWS_ACCESS_KEY_ID = "YOUR_ACCESS_KEY_ID"
AWS_SECRET_ACCESS_KEY = "YOUR_SECRET_ACCESS_KEY"
BUCKET_NAME = "ax-s3-demo" # probably a different bucket here too
service = boto3.client("s3", endpoint_url="https://fly.storage.tigris.dev",
aws_access_key_id=AWS_ACCESS_KEY_ID,
aws_secret_access_key=AWS_SECRET_ACCESS_KEY,
)
for obj in service.list_objects_v2(Bucket=BUCKET_NAME)["Contents"]:
print(obj["Key"])
service.download_file(BUCKET_NAME, obj["Key"], obj["Key"])
After running this I have one json file locally, as expected.
Overall this could be a very cost effective method to pass on data or files between services.