Scrape a Website using Playwright Python
I build a crawler to get the waterlevels of rivers in Baden-Württemberg every 15 minutes. There is no real API, but I wanted to plot the data over time. The page is rendered using Javascript which made a beautifulsoup solution not possible.
But there is Playwright for Python.
Playwright works with multiple browsers and supports an interactive mode.
As example for the waterlevel website:
import asyncio from playwright.async_api import async_playwright async def main(): async with async_playwright() as p: browser = await p.chromium.launch(headless=False) page = await browser.new_page() await page.goto("https://www.hvz.baden-wuerttemberg.de/overview.html") print(await page.title()) # pause to inspect the page await page.pause() await browser.close() asyncio.run(main())
This starts an interactive chromium. F12 is available and every page.pause() is a breakpoint.
The page is paused after printing the title of the website.
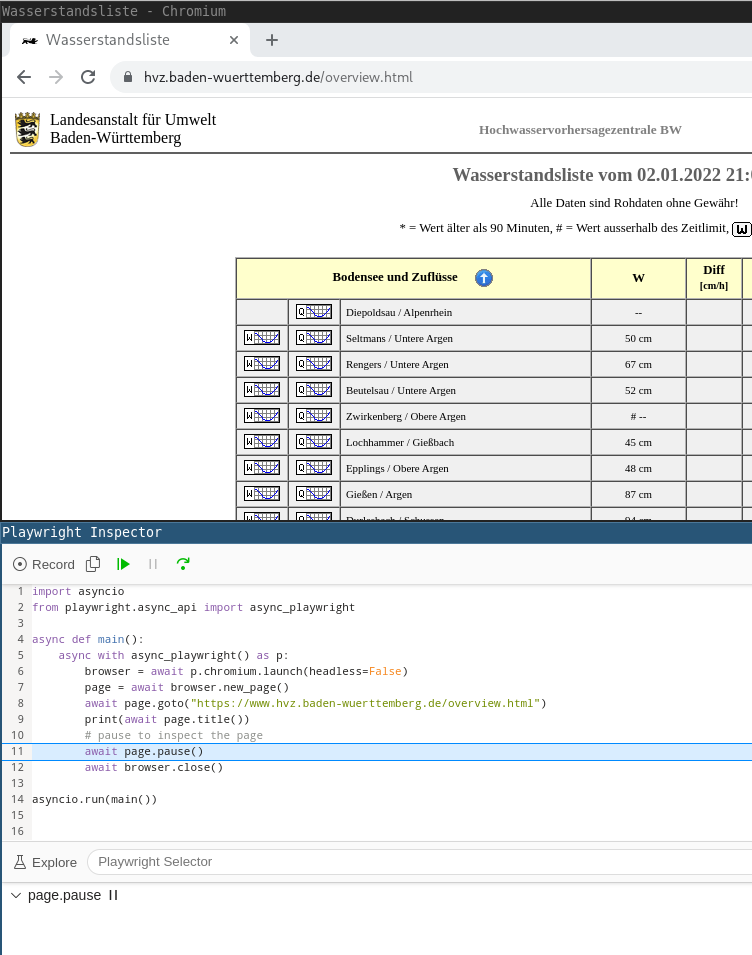
The interactivity and full debug capabilities allow a lot easier development than using beautifulsoup on a downloaded HTML file.
The crawler is using GitHub Actions to download the data using schedules.
The full code of the crawler: https://github.com/mfa/waterlevel-bw/blob/main/crawler/run.py.