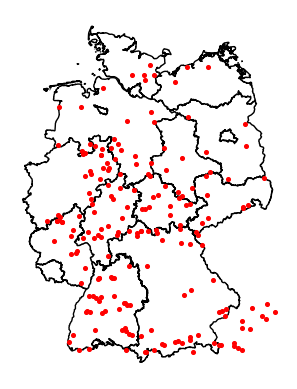
Spa towns near Rivers
As followup to the previous post, I was asked if spa towns are near rivers. Let's see if we can answer this by using overpass, shapely and geopandas.
In the previous blog post I used a bounding box to get all spa towns in Germany. There is a better way by using area ids queried via Nominatim. For Example select all rivers in Germany this way:
from OSMPythonTools import overpass from OSMPythonTools.nominatim import Nominatim nominatim = Nominatim() # get areaId for Germany area_id = nominatim.query("Germany").areaId() api = overpass.Overpass() query = overpass.overpassQueryBuilder( # use area_id instead of bbox area=area_id, # some rivers are relations elementType=["way", "relation"], # only natural rivers selector='"natural"="water"', out="body", includeGeometry=True, ) result = api.query(query, timeout=300) # write to json json.dump(result.toJSON()["elements"], open("rivers.json", "w"), indent=2, ensure_ascii=False)
The selector is "natural=water", more information about waterways in the openstreetmap wiki.
This query will take a bit of time to run and writes a lot of files in the cache folder.
To count the datasets we could use jq:
A lot of natural waterways!
For testing I selected the first 3 rivers and wrote them into an extra file to speed up development of the following Python code:
Next calculate the distance between every river and every spa town. We have latitude/longitude from Openstreetmap and can calculate which river is the nearest, but the resulting values are the euclidian distance (and not in meters).
The following code is a non-optimized brute-force approach and would be a lot faster by limiting the rivers with their bounding boxes. But for now start with the least code possible.
import json import geopandas as gpd from shapely import LineString, Point, Polygon from tqdm import tqdm # loading spas def _spas(): for d in json.load(open("spa_towns.json")): yield { "id": d["id"], "name": d.get("tags", {}).get("name", f"--{d['id']}"), "geometry": Point(d["lat"], d["lon"]), } df = gpd.GeoDataFrame.from_records(_spas()) print("loading rivers") rivers = json.load(open("rivers.json")) def get_nearest(row): print(row["name"]) shortest_distance = 100 nearest_river = None for river in tqdm(rivers): # filter everything that has no wikidata entry if river.get("tags", {}).get("wikidata") is None: continue river_name = river.get("tags", {}).get("name", f"noname-{river['id']}") if river.get("type") == "way": ways = [river] elif river.get("type") == "relation": # relations contain more than one way ways = river.get("members") else: # don't calculate anything continue for way in ways: if not way.get("geometry"): continue d = row["geometry"].distance( LineString([(i["lat"], i["lon"]) for i in way.get("geometry")]) ) if d < shortest_distance: nearest_river = river_name shortest_distance = d return f"{nearest_river} ({shortest_distance})" # fill a new column with nearest_river and distance in brackets df["nearest_river"] = df.apply(lambda row: get_nearest(row), axis=1) # write data as GeoJson df.to_file("spa_river.json", driver="GeoJSON")
The code filters on only rivers/lakes with a wikidata entry, to get rid of a lot of "Kneipp-Bad" or "Teich mit Enten" or for Bad Canstatt the "Brillenpinguine" in the local zoo.
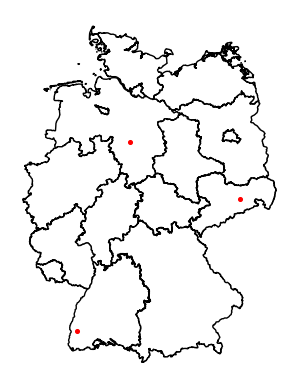
Looking at some of the results:
Bad Wildbad is next to the river "Enz" but the nearest river here is Nagoldtalsperre (0.19372965182449883) which is not that far away, but not the "Enz". The Enz is actually missing because it is not tagged with natural="water".
Bad Honnef is next to the "Rhein" (Rhine) but the value we get is Blauer See (0.11373349109158684).
Bad Teinach should be next to the river "Nagold", but the value is Gültlinger See (0.09095129123228435).
So the result is not good enough to answer the question if a river is near every spa town. The rivers would have to be manually filtered and maybe even selected beforehand. For automatic selection with only Openstreetmap there is not enough information.