Using Datasette JSON Write API
In my previous post I described how I used GPT-4o-mini to detect digits on a display.
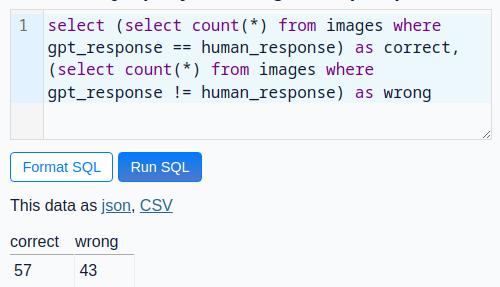
To evaluate the accuracy of the LLM I wanted to manually verify the GPT responses.
For this I needed to see the image and the value from the LLM, so a page in a Browser was the obvious choice.
All my data is already in a Datasette, so I looked what seems the easiest way to solve this.
Datasette 1.0 will get a new write API which is the perfect fit to write an update into one field in the SQLite database.
So I installed datasette==1.0a14 which is the current version when writing this post.
The JSON write API needs a token which I will add to a field on the website (seen in the screenshot below). To create this token the Datasette instance needs a secret for hashing.
I created my token this way (obviously with a real secret):
And started the Datasette with the secret and a templates folder with pages/label.html in it.
Shot of the label interface in action:
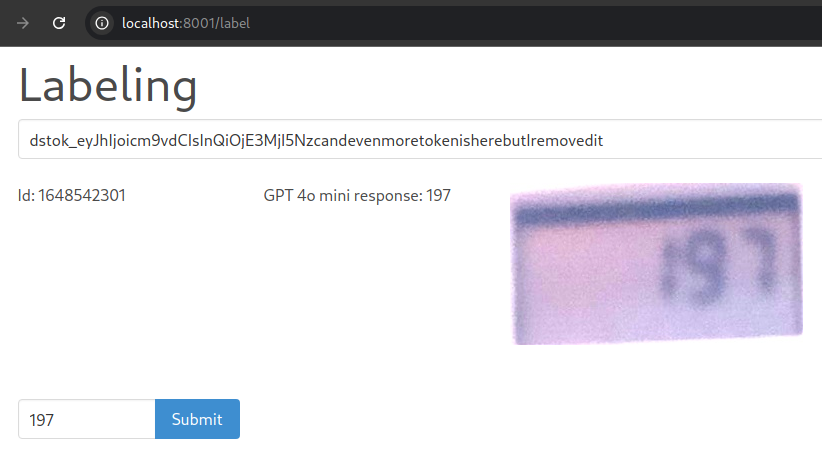
The full code of my label.html with fetching the next entry and update on submit.
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /><title>Label</title> <link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bulma@0.9.4/css/bulma.min.css"> </head> <body> <div class="container"> <div class="is-full hero"> <div class="hero-title"> <h2 class="is-size-1">Labeling</h2> <form autocomplete="off"> <div class="columns"> <div class="column is-12"> <div class="field has-addons"> <div class="control is-expanded"> <input id="token" class="input" type="text" placeholder="Insert token"> </div> </div> </div> </div> <div class="columns"> <div class="column is-3"> Id: <span id="id"></span> </div> <div class="column is-3"> GPT 4o mini response: <span id="gpt_response"></span> </div> <div class="column is-6"> <span id="image"></span> </div> </div> <div class="columns mt-5"> <div class="column is-3"> <div class="field has-addons"> <div class="control is-expanded"> <input id="digits" class="input" type="text"> </div> <div class="control"> <button id="submit" class="button is-info is-primary">Submit</button> </div> </div> </div> </div> </form> </div> </div> </div> </body> <script type="text/javascript"> function get_next() { return fetch('http://localhost:8001/minol/images.json?display_image__notblank=1&gpt_response__notblank=1&human_response__isnull=1&_shape=array&_nocol=thumbnail&_size=1') .then((response) => { response.json().then((data) => { document.getElementById('digits').value = data[0]['gpt_response'] document.getElementById('id').innerHTML = data[0]['id'] document.getElementById('gpt_response').innerHTML = data[0]['gpt_response'] document.getElementById('image').innerHTML = "<img src='data:image/jpeg;base64," + data[0]["display_image"]["encoded"] + "'/>" })}) .catch(error => console.log(error))} function update() { const id=document.getElementById('id').innerHTML console.log(document.getElementById('token').value) fetch('/minol/images/'+id+'/-/update', { method: 'post', headers: { 'Content-Type': 'application/json', 'Authorization': 'Bearer ' + document.getElementById('token').value }, body: JSON.stringify({ "update": { "human_response": document.getElementById('digits').value, }})}) .then((response) => { if(response.status === 200){ get_next() } else { response.json().then((data) => { console.log(data) })}}) .catch(error => console.log(error))} window.onload = function () { get_next() document.getElementById("submit").onclick = function() { event.preventDefault() update()} } </script> </html>
The JSON write API part in update() was as described in the docs.
If the result is 200 then a new row is fetched.
Otherwise the error will be printed to the console, which is good enough for me.
Because the GPT value is already prefilled the whole labeling procedure was fast.
Of course I approved a wrong value once.
To fix this I updated the human_response to NULL in a sqlite3 shell, so the dataset will return eventually.
If this happens more often a way to reopen the previous row would be nice.
I may add this, but only if it annoys me enough.